
👉 My take: We keep scaling models bigger and bigger, but here's the thing: without memory, your agents keep repeating the same expensive computations. Add memory, and suddenly they're actual teammates who learn.
The Problem: Agents Forget Everything
When you integrate AI agents into your development workflow, you quickly hit a fundamental limitation: they're stateless.
Every request triggers the same expensive operations: scanning files, analyzing code structure, processing dependencies. Ask the same question an hour later, and you're burning the same compute resources for identical results.
This isn't just inefficient. It's architecturally broken. Memory is what fixes this.
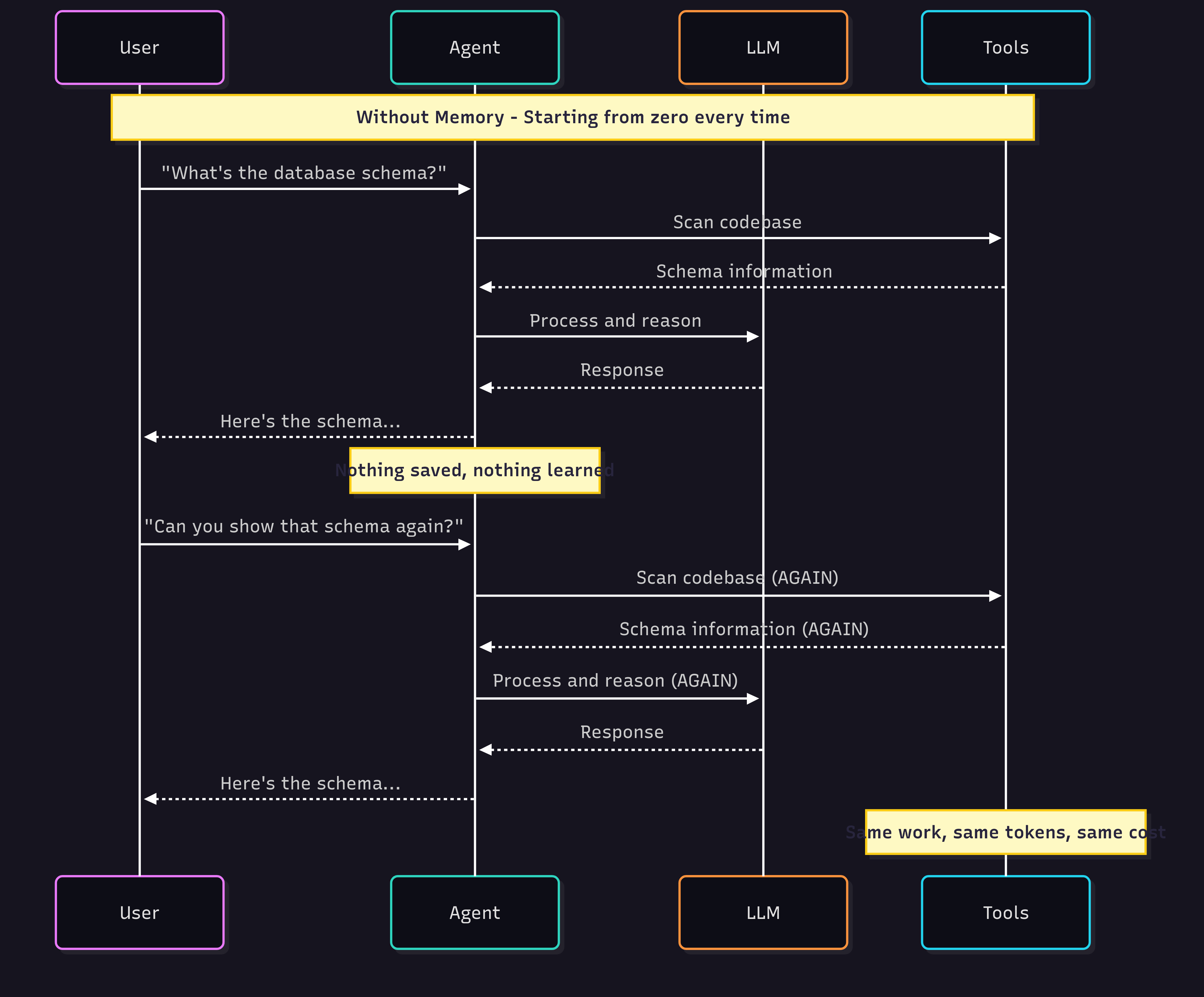
Why Memory Changes Everything
Memory transforms one-time calculations into persistent knowledge. Your agent stops redoing work and starts building on what it knows.
- Performance boost: Skip the redundant stuff
- Cost savings: Stop burning tokens on repeat tasks
- Actually useful: Conversations that make sense
Think about onboarding a junior dev. Week one they're slow, asking everything twice. Month later? They know the codebase, the patterns, the gotchas. That's what memory gives your agents.
📚 Check out how VoltAgent does this in the Memory Overview Documentation
Types of Memory (Because One Size Doesn't Fit All)
Memory isn't monolithic, you need different types for different jobs:
What it is: The LLM's context window
Think of it as: Your IDE's open tabs - what you're actively working on
Example: "We're debugging the auth flow" (remembered during this conversation)
Limitation: Gone when the context resets, usually after a few thousand tokens
What it is: Persisted knowledge in databases or vector stores
Think of it as: Your team's knowledge base that never forgets
Example: "This user prefers TypeScript examples" (remembered across sessions)
Limitation: Needs active management to stay relevant and not bloat
What it is: Event and interaction logs from past experiences
Think of it as: Your sprint retrospective notes - what happened and when
Example: "Deploy failed with OOM error last Tuesday at 3pm"
Limitation: Can grow huge if you don't prune old events
What it is: Insights and patterns your agent figures out over time
Think of it as: Your senior dev's intuition about the codebase
Example: "The payment service always slows down after 5pm EST"
Limitation: Can become outdated as systems change
Mix these together and your stateless tool becomes a learning system.
Here's What Actually Happens
Agents with memory don’t need to start from zero each time. The first request might require scanning and reasoning, but the result is saved.
Next time, the agent can recall instantly and no redundant work, faster response.
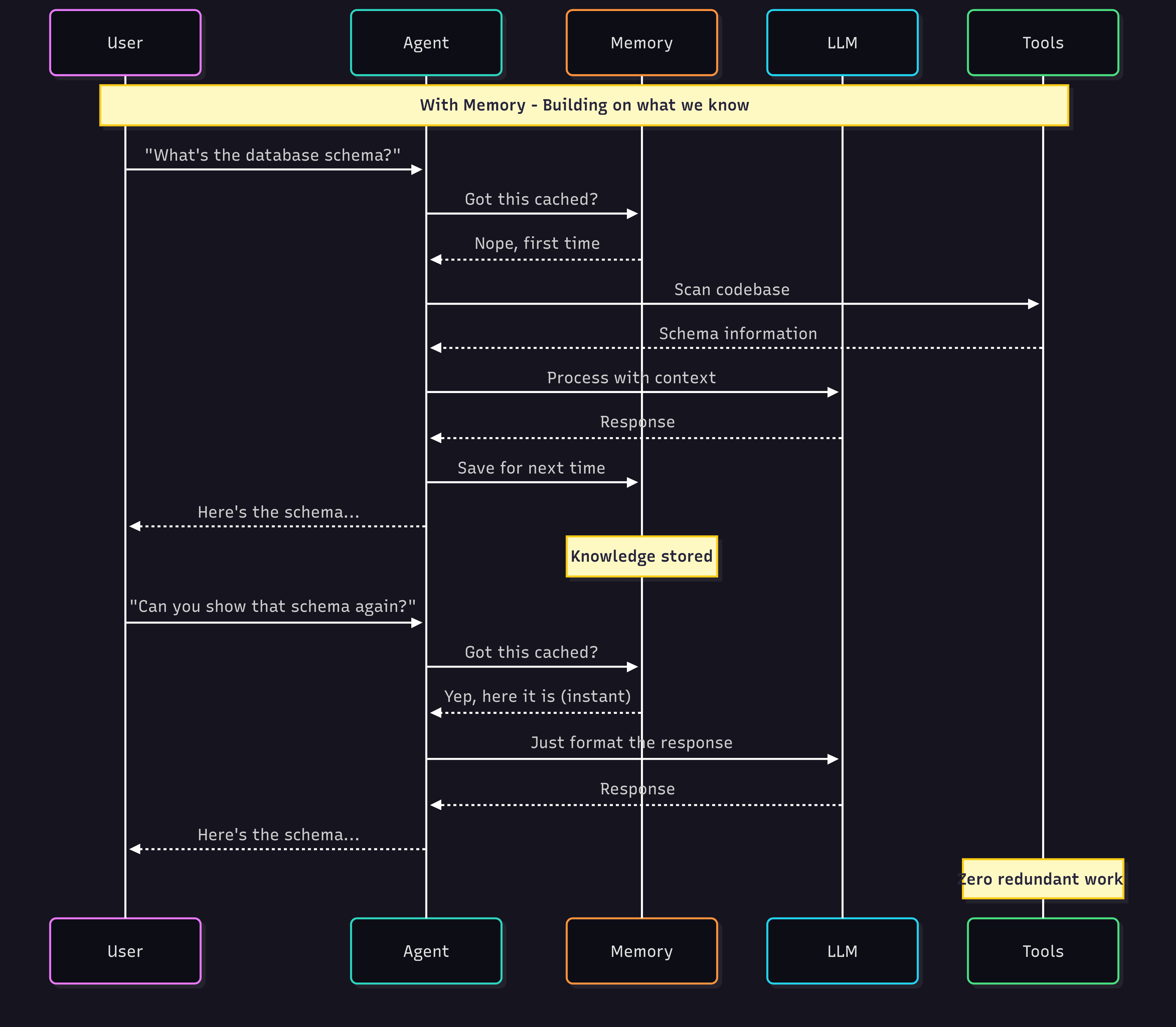
The Classic Trade-off (That Memory Solves)
Building agents, you usually pick your poison:
RAG (Retrieval-Augmented Generation)
- The good: Fast, cheap, works great for simple lookups
- The bad: Only as good as your retrieval, falls apart on complex tasks
Tool-using Agents
- The good: Can handle anything, great for complex workflows
- The bad: Slow, expensive, lots of back-and-forth
Memory breaks this trade-off. Cache the expensive operations, return instant results for known queries, only do the heavy lifting for genuinely new problems. Your agents get faster AND smarter over time.
🚀 VoltAgent handles this with pluggable Memory Providers
The Hard Truth: Knowledge Management is Hard
Look, storing data is easy. Any database can do that. The hard part? Keeping that knowledge useful, accurate, and relevant.
- Cache invalidation: Yeah, the hardest problem in CS shows up here too
- Conflicting info: What happens when new data contradicts old knowledge?
- Staying in sync: Code changes, docs update, your memory needs to keep up
This is why memory isn't just slapping Redis on your agent. It's an ongoing knowledge management problem.
How VoltAgent Tackles This
Instead of forcing one solution, VoltAgent gives you options:
- LibSQL/SQLite: Zero-config local storage, perfect for development
- PostgreSQL: Battle-tested, production-ready
- Supabase: Managed Postgres with bells and whistles
- In-Memory Storage: For when you need speed over persistence
Where Memory Actually Matters
Let me show you where this makes a real difference:
- Support bots: Stop asking customers to repeat themselves
- Code assistants: Remember the codebase structure, stop rescanning everything
- CI/CD pipelines: Learn from past runs, skip unnecessary steps
The difference is night and day. Without memory, you've got a fancy Q&A bot. With memory, you've got a colleague who actually learns.
Getting Started with VoltAgent Memory
VoltAgent makes memory implementation surprisingly simple. By default, agents come with zero-configuration local persistence that just works.
The Basics: Zero-Config Memory
import { Agent } from "@voltagent/core";
import { VercelAIProvider } from "@voltagent/vercel-ai";
import { openai } from "@ai-sdk/openai";
const agent = new Agent({
name: "My Assistant",
instructions: "You are a helpful assistant",
llm: new VercelAIProvider(),
model: openai("gpt-4o"),
// No memory config needed - automatically uses .voltagent/memory.db
});
This automatically:
- Creates a
.voltagentfolder in your project root - Initializes SQLite storage at
.voltagent/memory.db - Handles all conversation persistence
Critical: User and Conversation Context
The most important part? Providing proper user context. Without userId, your memory won't work correctly:
// ✅ Correct: Memory properly isolated per user
const response = await agent.generateText("What's the status?", {
userId: "user-123", // Required for memory isolation
conversationId: "support-chat-1", // Keeps conversations separate
});
// ❌ Wrong: Memory won't work properly
const response = await agent.generateText("What's the status?");
Choosing the Right Storage
Different scenarios need different storage backends:
// Development: Fast iteration with in-memory storage
import { InMemoryStorage } from "@voltagent/core";
const devAgent = new Agent({
// ... config
memory: new InMemoryStorage({ storageLimit: 100 }),
});
// Production: PostgreSQL for scale
import { PostgreSQLStorage } from "@voltagent/postgres";
const prodAgent = new Agent({
// ... config
memory: new PostgreSQLStorage({
connectionString: process.env.DATABASE_URL,
}),
});
Learn More
Ready to implement memory in your agents? Check out:
- Memory Overview Documentation for the complete guide
- Memory Providers for all storage options
- Interactive Tutorial to see memory in action